
转一篇 Dropbox 关于 BBRv2 在边缘网络的评估报告,先剧透评估结果:BBRv2 比 BBRv1 慢。
Spoiler alert: BBRv2 is slower than BBRv1 but that’s a good thing.
BBRv1 Congestion Control
Three years have passed since “Bottleneck Bandwidth and Round-trip” (BBR) congestion control was released. Nowadays, it is considered production-ready and added to Linux, FreeBSD, and Chrome (as part of QUIC.) In our blogpost from 2017, “Optimizing web servers for high throughput and low latency,” we evaluated BBRv1 congestion control on our edge network and it showed awesome results:

Desktop client’s download bandwidth during BBR experiment in 2017.
Since then, BBRv1 has been deployed to Dropbox Edge Network and we got accustomed to some of its downsides. Some of these were eventually fixed, like it being measurably slower for Wi-Fi users. Other tradeoffs were quite conceptual: BBRv1’s unfairness towards loss-based congestion controls (e.g. CUBIC, Compound), RTT-unfairness between BBRv1 flows, and (almost) total disregard for the packet loss:

Initial BBRv1 deployment: some boxes have >6% packet loss.
BBR developers (and IETF ICCRG) were, of course, also quite aware of these problems and actively worked on solutions. Following issues were identified:
- Low throughput for Reno/CUBIC flows sharing a bottleneck with bulk BBR flows
- Loss-agnostic; high packet loss rates if bottleneck < 1.5*BDP
- ECN-agnostic
- Low throughput for paths with high degrees of aggregation (e.g. wifi)
- Throughput variation due to low cwnd in PROBE_RTT
Meet BBR version 2
BBRv2 aims to solve some major drawbacks of the first version, from lack of concern for packet loss to not giving enough room for new flows to enter. Plus, it also enhances network modeling with aggregation/in-flight parameters and adds experimental support for ECN (explicit congestion notification).
| CUBIC | BBR v1 | BBR v2 | |
|---|---|---|---|
| Model parameters for the state machine | N/A | Throughput, RTT | Throughput, RTT, max aggregation, max inflight |
| Loss | Reduce cwnd by 30% on window by any loss | N/A | Explicit loss rate target |
| ECN | RFC3168 (Classic ECN) | N/A | DCTCP-inspired ECN |
| Startup | Slow-start until RTT rises (Hystart) or any loss | Slow-start until throughput plateaus | Slow-start until throughput plateaus or ECN/Loss rate > target |
As BBRv2 is getting closer to release, we decided to take it for a spin on Dropbox Edge Network and see how it handles our workloads. But before we get into experimental results (and somewhat pretty pictures), lets cover disclaimers and test setup.
Disclaimers
Not a low-latency experiment
This experiment was aimed at high-throughput workloads, not latency-sensitive ones. All TCP connections and nginx logs mentioned in the post were filtered by having at least 1Mb of data transferred.
Eventually, we may decide on deploying BBRv2 internally in datacenters (possibly even with ECN support) for RPC traffic but that is outside the scope of this post.
Not a single connection test
This experiment was performed in a single PoP (point of presence), but on boxes handling millions of connections, so no single connection troubleshooting, tcptrace drill-downs, nor tcpdumps were involved. What follows is a mix of summary statistics, Jupyter notebooks, pandas, and seaborn.
Even though seaborn facilitates the creation of pretty graphs, I’ve mostly failed at that, so sorry in advance for the poor graphs’ quality. OTOH, at least it’s not xkcd-style =)
This is not a lab test
This is a real-world experiment on our edge network. If you want to test BRRv2 (or any other congestion control) in a lab environment, we would recommend using github.com/google/transperf, that allows “Testing TCP performance over a variety of emulated network scenarios (using netem), including RTT, bottleneck bandwidth, and policed rate that can change over time,” like this:
![]()
An example of a transperf run.
Test setup
We used a set of machines in our Tokyo PoP and tested the following combinations of kernels/congestion control algorithms:
- 5.3 kernel, cubic
- 5.3 kernel, bbr1
- 5.3 kernel, bbr2
- 4.15 kernel, bbr1
All of the servers are using a combination of mq and sch_fq qdiscs with default settings.
Kernel is based on Ubuntu-hwe-edge-5.3.0-18.19_18.04.2 with all the patches from the [v2alpha-2019-11-17](https://github.com/google/bbr/tree/v2alpha-2019-11-17) tag:

The set of BBRv2 patches on top of Ubuntu-hwe-edge-5.3.0-18.19_18.04.2
We’ve also applied “tcp: Add TCP_INFO counter for packets received out-of-order” for the ease of merging and “[[DBX] net-tcp_bbr: v2: disable spurious warning](https://gist.github.com/SaveTheRbtz/63b6e416865837306b11490b6f51eb2a)” to silence the following warning:
WARNING: CPU: 0 PID: 0 at net/ipv4/tcp_bbr2.c:2426 bbr_set_state [tcp_bbr2]
All the graphs in the post were generated from either connection-level information from ss -neit sampling, machine-level stats from /proc, or server-side application-level metrics from web-server logs.
Keeping the kernel up-to-date
Newer kernels usually bring quite a bit of improvement to all subsystems including the TCP/IP stack.
For example, if we compare 4.15 performance to 5.3, we can see that the latter has ~15% higher throughput, based on the web server logs:

4.15 vs 5.3 median file download throughput from Nginx point of view.
Most likely candidates for this improvement are “tcp_bbr: adapt cwnd based on ack aggregation estimation” (that fixed the Wi-Fi slowness mentioned above) and “tcp: switch to Early Departure Time model” (which we’ll talk about later in the AFAP section.)
Recent Linux kernels also include mitigations for the newly discovered CPU vulnerabilities. We highly discourage disabling them (esp. on the edge!) so be prepared to take a CPU usage hit.
Keeping userspace up-to-date
Having recent versions of userspace is quite important if you are using newer versions of the kernel compared to what your OS was bundled with. Especially so for packages like ethtool and iproute2.
Just compare the output of an ss command with the old version:
$ ss -tie
ts sack bbr rto:220 rtt:16.139/10.041 ato:40 mss:1448 cwnd:106
ssthresh:52 bytes_acked:9067087 bytes_received:5775 segs_out:6327
segs_in:551 send 76.1Mbps lastsnd:14536 lastrcv:15584 lastack:14504
pacing_rate 98.5Mbps retrans:0/5 rcv_rtt:16.125 rcv_space:14400
…versus the new one:
$ ss -tie
ts sack bbr rto:220 rtt:16.139/10.041 ato:40 mss:1448 pmtu:1500
rcvmss:1269 advmss:1428 cwnd:106 ssthresh:52 bytes_sent:9070462
bytes_retrans:3375 bytes_acked:9067087 bytes_received:5775
segs_out:6327 segs_in:551 data_segs_out:6315 data_segs_in:12
bbr:(bw:99.5Mbps,mrtt:1.912,pacing_gain:1,cwnd_gain:2)
send 76.1Mbps lastsnd:9896 lastrcv:10944 lastack:9864
pacing_rate 98.5Mbps delivery_rate 27.9Mbps delivered:6316
busy:3020ms rwnd_limited:2072ms(68.6%) retrans:0/5 dsack_dups:5
rcv_rtt:16.125 rcv_space:14400 rcv_ssthresh:65535 minrtt:1.907As you can see, the new ss version has all the goodies from the kernel’s [struct **tcp_info**](https://elixir.bootlin.com/linux/v5.3.8/source/include/uapi/linux/tcp.h#L206), plus the internal BBRv2 state from the [struct **tcp_bbr_info**](https://elixir.bootlin.com/linux/v5.3.8/source/include/uapi/linux/tcp.h#L191). This adds a ton of useful data that we can use even in day-to-day TCP performance troubleshooting, for example, insufficient sender buffer and insufficient receive window/buffer stats from the “tcp: sender chronographs instrumentation” patchset.
Experimental results
Low packet loss
First things first, immediately after enabling BBRv2 we observe an enormous drop in retransmits. Still not as low as CUBIC, but a great improvement. Also, given that BBR was designed to ignore non-congestion induced packet loss, we can probably say that things work as intended.

RetransSegs %, for Cubic, BBRv1, and BBRv2.
If we dig deeper and look at ss stats we can see that generally, BBRv2 has way lower packet loss than BBRv1 (note the logarithmic scale) but still way higher than CUBIC:
![]()
![]()
One strange experimental result is that BBRv2 has connections with >60% packet loss, which are present neither on BBRv1 nor CUBIC machines. Looking at some of these connections closer does not reveal any obvious patterns: connections with absurdly large packet loss come from different OS’es (based on Timestamp/ECN support,) connections types (based on MSS,) and locations (based on RTT.)
Aside from these outliers, retransmissions are lower across all RTTs:

Somehow, hosts using BBRv2 observe a lower degree of reordering, though this may be a side effect of fewer segments in-flight:

Throughput
From the Traffic team perspective one of our SLIs for edge performance is end-to-end client-reported file download speed. For this test, we’ve been using server-side file download speed as the closest proxy.
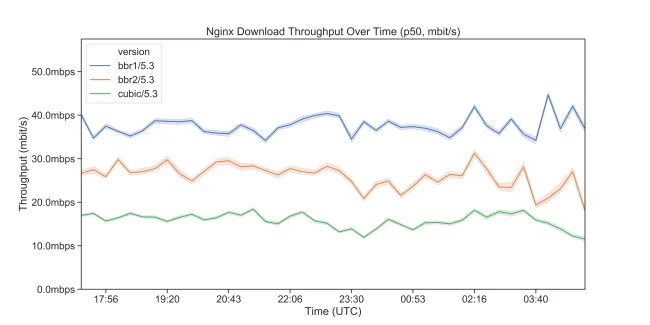
Here are the results comparing file download speed from the nginx point of view: BBRv2 versus both BBRv1 and CUBIC:

Median nginx throughput, 95% ci (for files >1Mb.)

P75 nginx throughput, 95% ci (for files >1Mb.)
For lower percentiles of connection speeds, BBRv2 has performance is closer to CUBIC and for higher ones it starts getting closer to BBRv1.
Connection-level stats confirm that BBRv2 has lower bandwidth than BBRv1, but still higher than CUBIC:


So, is BBRv2 slower? It is, at least to some extent. So, what are we getting in return? Based on connection stats, quite a lot actually. We’ve already mentioned lower packet loss (and therefore higher “goodput”), but there is more.
Fewer packets in-flight
We’ve observed way fewer “unacked” packets which is a good proxy for bytes in-flight. BBRv2 looks way better than in BBRv1, and even slightly better than CUBIC:


Plotting RTT (round-trip time) versus in-flight shows that in BBRv1 case amount of data in-flight tends to be dependent on the RTT, which looks fixed in BBRv2:


As one of BBR co-authors, Neal Cardwell, explains:
In all of the cases I’ve seen with unfairness due to differing min_rtt values, the dominant factor is simply that with BBRv1 each flow has a cwnd that is basically 2_bw_min_rtt, which tends to try to maintain 1_bw_min_rtt in the bottleneck queue, which quite directly means that flows with higher min_rtt values maintain more packets in the bottleneck queue and therefore get a higher fraction of the bottleneck bandwidth. The most direct way I’m aware of to improve RTT fairness in the BBR framework is to get rid of that excess queue, or ensure that the amount of queue is independent of a flow’s min_rtt estimate.
Receive Window Limited connections
We also observe that BBRv2 connections spend way less time being “receive window limited” than BBRv1 and CUBIC connections do:


I would assume that CUBIC without sch_fq would look even worse than BBRv1.Lower RTT
As a bonus BBRv2 also has a lower RTT than BBRv1, but strangely higher than CUBIC:


Correlations between Min RTT and Bandwidth
If we construct Min RTT vs Bandwidth graph then vertical bands represent a network distance from user to our Tokyo PoP while horizontal bands represent common Internet speeds:

bbr_mrtt vs bbr_bw scatterplot of all BBR flows in the experiment (both BBRv1 and BBRv2.)
What’s interesting here is the exponentially decaying relationship between MinRTT and bandwidth for both BBRv1 and BBRv2. This means that there are some cases where bandwidth is artificially limited by RTT. Since this behavior is the same between BBRv1 and BBRv2 we did not dig too much into it. It’s likely though that bandwidth is being artificially limited by the user’s receive window.
The 130+ ms RTT band represents cross-Pacific traffic and hence very likely a GSLB failure to properly route users to the closest PoP. We’ll talk about how we are utilizing RUM data to avoid that in the following blog post.
CPU Usage Improvements
Previously, BBRv1 updated the whole model on each ACK received, which is quite a lot of work given the millions of ACKs that an average server receives. BBRv2 has an even more sophisticated network path model but it also adds a fast path that skips model updates for the application-limited case. This, in theory, should greatly reduce CPU usage on common workloads.
ACK fast-path is not the only optimization that was made, feel free to check out the full list of optimizations in the BBR’s IETF ICCRG 106 presentation.
In our tests, though, we did not see any measurable difference in CPU usage between BBRv1 and BBRv2, but this is likely due to BBRv2 having quite a lot of debug code enabled (for now:)

Idle CPU on BBRv1 vs BBRv2.
Pay special attention to the CPU usage if you are testing BBR with ECN enabled since it may render GRO/GSO unusable for high packet loss scenarios.
Conclusions
In our testing BBRv2 showed the following properties:
- Bandwidth is comparable to CUBIC for users with lower percentiles of Internet speeds.
- Bandwidth is comparable to BBRv1 for users with higher percentiles of Internet speeds.
- Packet loss is 4 times lower compared to BBRv1*; still 2x higher than CUBIC.
- Data in-flight is 3 times lower compared to BBRv1; slightly lower than CUBIC.
- RTTs are lower compared to BBRv1; still higher than CUBIC.
- Higher RTT-fairness compared to BBRv1.
Overall, BBRv2 is a great improvement over the BBRv1 and indeed seems way closer to being a drop-in replacement for Reno/CUBIC in cases where one needs slightly higher bandwidth. Adding experimental ECN support to that and we can even see a drop-in replacement for Data Center TCP (DCTCP).
*_Minus the 0.0001% of outliers with a >60% packet loss._
We’re hiring!
If you are still here, there is a good chance that you actually enjoy digging deep into the performance data and you may enjoy working on the Dropbox Traffic team! Dropbox has a globally distributed Edge network, terabits of traffic, and millions of requests per second. All of which is managed by a small team in Mountain View, CA.
The Traffic team is hiring both SWEs and SREs to work on TCP/IP packet processors and loadbalancers, HTTP/gRPC proxies, and our internal gRPC-based service mesh. Not your thing? Dropbox is also hiring for a wide variety of engineering positions in San Francisco, New York, Seattle, Tel Aviv, and other offices around the world.
Appendix A. BBRv2 Development
Development happens on github.com/google/bbr. Discussions are happening on the bbr-dev mailing list.
Here is the list of BBR design principles (bold means it’s new v2):
- Leave headroom: leave space for entering flows to grab
- React quickly: using loss/ECN, adapt to delivery process now to maintain flow balance
- Don’t overreact: don’t do a multiplicative decrease on every round trip with loss/ECN
- Probe deferentially: probe on a time scale to allow coexistence with Reno/CUBIC
- Probe robustly: try to probe beyond estimated max bw, max volume before we cut est.
- Avoid overshooting: start probing at an inflight measured to be tolerable
- Grow scalably: start probing at 1 extra packet; grow exponentially to use free capacity
Here are some notable milestones in BBRv2 development to date:
- BBR v2 algorithm was described at IETF 104: Prague, Mar 2019 [video] [slides]
- BBR v2 open source release was described at IETF 105: Montreal, July 2019 [video] [slides]
- BBR v2 performance improvements and fixes IETF 106: Singapore, Nov 2019 [video] [slides]
Appendix B. Explicit Congestion Notification
ECN is a way for the network bottleneck to notify the sender to slow down before it runs out of buffers and starts “tail dropping” packets. Currently, though, ECN on the Internet is mostly deployed in a so-called “passive” mode. Based on Apple’s data 74+% most popular websites “passively” support ECN. On our Tokyo PoP, we currently observe 3.68% of connections being negotiated with ECN, 88% of which have an ecnseen flag.
There are a lot of upsides to using ECN both internally and externally, as described in “The Benefits of Using Explicit Congestion Notification (ECN)” RFC.
One of the downsides of Classic ECN (a.k.a RFC3168) is that it is too prescriptive about explicit congestion signal:
Upon the receipt by an ECN-Capable transport of a single CE packet, the congestion control algorithms followed at the end-systems MUST be essentially the same as the congestion control response to a *single* dropped packet.
...
The indication of congestion should be treated just as a congestion loss in non-ECN-Capable TCP. That is, the TCP source halves the congestion window "cwnd" and reduces the slow start threshold "ssthresh".
(And for a good reason, since any difference in behavior between explicit (CE mark) and implicit (drop) congestion will definitely lead to unfairness.)
Other RFCs, like the “Problem Statement and Requirements for Increased Accuracy in Explicit Congestion Notification (ECN) Feedback,” call out the low granularity of classic ECN that is only able to feedback one congestion signal per RTT. Also for a good reason: DCTCP (and BBRv2) implementation of ECN greatly benefits from its increased accuracy:

M. Alizadeh et al. Data Center TCP (DCTCP).
DCTCP’s custom interpretation of CE leads to a total unfairness towards classic congestion control algorithms.
RFC8311, “Relaxing Restrictions on Explicit Congestion Notification (ECN) Experimentation” tries to fix this by relaxing this requirement so that implementations are free to choose behavior outside of one specified by Classic ECN.
Talking about ECN it’s hard to not mention that there is also a “congestion-notification conflict” going over a single code point (a half a bit) of space in the IP header between the “Low Latency, Low Loss, Scalable Throughput (L4S)” proposal and the bufferbloat folks behind the “The Some Congestion Experienced ECN Codepoint (SCE)” draft.
As Jonathan Corbet summarizes it:
These two proposals are clearly incompatible with each other; each places its own interpretation on the ECT(1) value and would be confused by the other. The SCE side argues that its use of that value is fully compatible with existing deployments, while the L4S proposal turns it over to private use by suitably anointed protocols that are not compatible with existing congestion-control algorithms. L4S proponents argue that the dual-queue architecture is necessary to achieve their latency objectives; SCE seems more focused on fixing the endpoints.
Time will show which, if any, draft is approved by IETF, in the meantime, we can all help the Internet by deploying AQMs (e.g. fq_codel, cake) to the network bottlenecks under our control.
There is an RFC for that too, namely, “IETF Recommendations Regarding Active Queue Management”, that has a whole section on AQMs and ECN.
Appendix C. Beyond As Fast As Possible
“Evolving from AFAP – Teaching NICs about time”
There is a great talk by Van Jacobson about the evolution of computer networks and that sending “as fast as possible” is not an optimal in today’s Internet and even inside a datacenter.

You can checkout slides and video of Van Jacobson’s netdev talk. Coverage is available from Julia Evans (@b0rk) and LWN.net (@BPismenny).
This talk is a great summary of the reasons why one might consider using pacing on the network layer and a delay-based congestion control algorithm.
Fair Queue scheduler
Quite often we mention that all our Edge boxes run with Fair Queue scheduler:
$ tc -s qdisc show dev eth0
qdisc mq 1: root
Sent 100800259362 bytes 81191255 pkt (dropped 122, overlimits 0 requeues 35)
backlog 499933b 124p requeues 35
qdisc fq 9cd7: parent 1:17 limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028 initial_quantum 15140 low_rate_threshold 550Kbit refill_delay 40.0ms
Sent 1016286523 bytes 806982 pkt (dropped 0, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
2047 flows (2044 inactive, 0 throttled)
6162 gc, 0 highprio, 43782 throttled, 2716 ns latency
...
We also mention that our main goal is not the fair queueing itself but pacing introduced by tc-fq.
Earlier fq implementations did add some jitter to TCP’s RTT estimations which can be problematic inside the data center since it will likely inflate p99s of RPC requests. This was solved in “tcp: switch to Early Departure Time model.”
Here is an example of pacing at work: let’s use [bpftrace](https://github.com/iovisor/bpftrace) to measure difference between packets are enqueued into the qdisc and dequeued from it:
# bpftrace qdisc-fq.bt
@us:
[0] 237486 | |
[1] 8712205 |@@@@@@@@@@@@@@@@@@@@ |
[2, 4) 21855350 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[4, 8) 4378933 |@@@@@@@@@@ |
[8, 16) 372762 | |
[16, 32) 178145 | |
[32, 64) 279016 | |
[64, 128) 603899 |@ |
[128, 256) 1115705 |@@ |
[256, 512) 2303138 |@@@@@ |
[512, 1K) 2702993 |@@@@@@ |
[1K, 2K) 11999127 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[2K, 4K) 5432353 |@@@@@@@@@@@@ |
[4K, 8K) 1823173 |@@@@ |
[8K, 16K) 778955 |@ |
[16K, 32K) 385202 | |
[32K, 64K) 146435 | |
[64K, 128K) 31369 | |
qdisc-fq.bt is a part of supplementary material to the “BPF Performance Tools: Linux System and Application Observability” book by Brendan Gregg.
Appendix D. Nginx Throughput Graphs














